
After exercising a bit of theory in a previous article, I wanted to evaluate the state of the art for C++20 Modules across different platforms 2 years after the new Standard was officially released. The main purpose of these articles is to investigate the “adoption friction” of this new language feature by evaluating the overall learning curve, which includes grasping both the theory and the practice, conditioned to the support offered by the tools currently available.
Although this is quite a complex feature, ideally the expectation is that with enough knowledge of the new concepts a developer should be able to use it only thru the language and transparently across platforms without hacking around to make it work. The examples presented here have been tested with the following compilers in their “stable” releases using the recommended flags to enable the modules functionality.
- GCC 12.1
- CLANG 14.0
- MSVC 19.32
All the builds were done with Compiler Explorer for convenience and practicality, excluded MSVC for which Visual Studio was used as it doesn’t seem fully supported in Compiler Explorer. Links to the generated build environments are provided for each example.
NOTES 1. The issues reported in the "Gotcha #" sections reflect the state of the art at the time of this writing. 2. Some good coding practices have been purposely omitted in the examples for the sake of brevity.
1. Importing and exporting
Modules’ main purpose is to encapsulate functionality that can be exposed by a public interface and used by clients thru an importing mechanism, so let’s see how this works with C++ in practice. Consider an example where we want to create a bank module implementing banking functionality. We could start with a simple implementation like the following
// EXAMPLE 1
// ----------------------------
// bank.cpp
// ----------------------------
export module bank;
export class account {
public:
int transact(int amount) {
balance+=amount;
return balance;
}
private:
int balance{0};
};
void check(account& a) { }
// ----------------------------
// main.cpp
// ----------------------------
import bank;
int main() {
account acc{};
auto bal = acc.transact(100);
}Our bank module is made up of just the primary module interface unit with a purview section defining an account class, which is exported, and a check() function, which is not exported as it’s used for internal operations. In order to use the module’s functionality, the client code (here the main function in a standard TU) imports the module by referencing its name. All the entities exported by its primary interface are then available for use.
The module in the above example is conceptually equivalent to the following code written using header files
// ----------------------------
// bank.h
// ----------------------------
class account {
public:
int transact(int amount) {
balance+=amount;
return balance;
}
private:
int balance{0};
};
void check(account& a) { }
// ----------------------------
// main.cpp
// ----------------------------
#include "bank.h"
int main() {
account acc{};
auto bal = acc.transact(100);
}However, there are differences in how the code can be used and how it’s built by the compiler. In the header example, the code from the bank.h file is read, processed and then simply pasted into the main.cpp translation unit. Everything in the header file is available to the including code and can potentially affect it in many ways.
For example, referencing the check() function is a legit operation since it is visible and accessible, even though that may not have been our intent (the function is purposely not inlined as there is no ODR violation here).
#include "bank.h"
int main() {
//...
check(acc); // OK: check() is visible
}This is because header files do not provide any sort of encapsulation and everything declared in there will be injected in the including unit “as is” and is potentially usable. In our example we don’t really want the check() function to be available to client code. But we may want to make it available to our internal implementation.
There are several ways to work around this problem with headers, such as putting non-public entities into separate and specifically labelled “internal headers” or using the namespace detail idiom. But these are just conventions and such details can still leak into user code indirectly thru the include chains and nothing prevents them from being potentially abused.
On the other hand, doing the same with the module will result in a compilation error
import bank;
int main() {
//...
check(acc); // ERROR: check() is undefined
}Contrary to header files, modules do provide physical encapsulation and only entities that are explicitly exported by its primary interface are available to the importing code.
Gotcha #1 The process of importing a module requires that a compiled BMI for the imported module be present when the consumer code is compiled in order for the symbols resolution to succeed. This dependency condition shows when building an application by requiring a specific compilation order. In the above examples, if the main TU ( main.cpp ) is compiled before the module units the build will fail. Also, these dependencies may pose issues in terms of scalability when using parallel builds. An interesting study about this potential problem can be found here.
Gotcha #2 Unlike other languages, such as Python and Java, where there is a well defined correspondence between the module names and the source files organization in the file system, C++ module units are not required to be named the same as the module they represent nor to obey to any kind of mapping. The C++ Standard does not impose any specific requirement in this regard and compilers can implement their own mapping mechanism. While such freedom follows the Standard's philosophy of not dealing with implementation details, the lack of an intuitive correspondence between module and file names may force developers to be aware of all these vendor-specific mappings or to use some sort of convention.
GCC was able to build the examples by just using the -std=c++20 -fmodules-ts switches. However, it required specifying the dependencies by providing the list of source files in the right order (try to change that order and it will fail).
CLANG required a bit of upfront research to figure out which options to use in addition to -std=c++20. It also required explicitly creating the dependencies between modules and compiling in specific ways depending on the module unit type.
MSVC was able to build the examples after changing the extension of the module interface file from .cpp to .ixx, as that’s how by default it recognizes interface units that require a BMI. It also requires several flags to compile the different unit types if used on the command line. However, the Visual Studio IDE makes things simpler as it automatically takes care of many things, including the dependencies.
1.1 Interfaces isolation
One of the drawbacks of working with header files is that the interfaces exposed thru them are very fragile. To realize the potential dangers of header inclusions, following is an example of how the meaning of the code can be completely changed
// ----------------------------
// fun.h
// ----------------------------
int GetObject(int pos, int* data) {
//...
return data[pos];
}
// ----------------------------
// lib.h
// ----------------------------
int GetObjectA(int size, void* data) {
//...
return size;
}
#if SOME_CONDITION
#define GetObject GetObjectA
#endif
// ----------------------------
// main.cpp
// ----------------------------
#include "fun.h"
#include "lib.h"
int main() {
int v[3] = {1, 2, 3};
//...
auto res = GetObject(1, v); // ?
}The program uses a GetObject function to retrieve some value of some object from a processed array, which is included by <fun.h>. However, another header <lib.h> is included (possibly indirectly) that defines a GetObject macro which, if some condition is met, redirects to a function with a compatible signature but doing a different thing!
Running the code will produce the correct result. But if the condition is met (for example by passing -DSOME_CONDITION=1 to the compiler) we’ll get an incorrect result as the behavior of the GetObject function has been completely changed.
To solve this kind of issue the most common solution is to manipulate the preprocessor using #pragmas in order to disable/enable the offending macro, which is quite a dirty workaround. Instead, this problem could be more cleanly solved by using the strong encapsulation offered by modules. For example, the above code could be written in a modular fashion as follows
// EXAMPLE 1.1
// ----------------------------
// fun.cpp
// ----------------------------
export module fun;
export int GetObject(int pos, int* data) {
//...
return data[pos];
}
// ----------------------------
// lib.cpp
// ----------------------------
module;
#if SOME_CONDITION
#define GetObject GetObjectA
#endif
export module lib;
export int GetObjectA(int size, void* data) {
//...
return size;
}
// ----------------------------
// main.cpp
// ----------------------------
import fun;
import lib;
int main() {
int v[3] = {1, 2, 3};
//...
auto res = GetObject(1, v); // OK: returns as expected
}If we run this code it will produce the expected results regardless of whether the preprocessor condition is met. The “redirecting” macro is now visible only within the lib module and won’t leak into client code.
Even though such a macro-driven mechanism should not be used with modern C++ to manipulate the interfaces to begin with, sometimes in order to use legacy code we are forced to include header files that do nasty things. Modules can help reduce the risks in those situations.
The above example is actually very similar to a real-world scenario that I faced some time ago while developing on Windows, where the API defines in one of the SDK headers a GetObject macro that conditionally redirects to a different function depending on the used character set. It was indirectly introduced somewhere along the inclusion chain and silently broke the code.
1.2 Implementation units
With modules the interface and its implementation can be safely defined within the same unit as shown in the previous examples. This is a very common way of writing modules in many programming languages where there is no separation between declaration and definition, such as Python, Java, etc. A similar approach can be taken with C++ using “header only” coding style, but chances of breaking the ODR and other subtle issues are always around the corner as we’ve seen earlier.
However, often it is more convenient to split the interfaces and the implementations into different units and with C++ modules this can be done by separating the code into a (primary) module interface unit and a module implementation unit, as in the following example
// EXAMPLE 2
// ----------------------------
// bank.cpp (.ixx)
// ----------------------------
export module bank;
export class account {
public:
int transact(int amount);
private:
int balance{0};
};
void check(account& a);
// ----------------------------
// bank_impl.cpp
// ----------------------------
module bank;
int account::transact(int amount) {
//...
return balance;
}
void check(account& a) { }
// ----------------------------
// main.cpp
// ----------------------------
import bank;
int main() {
account acc{};
auto bal = acc.transact(100);
}This is conceptually similar to how it’s done with classic .h/.cpp pairs, but with the key difference of getting full encapsulation and isolation.
Another difference is in the handling of multiple definitions of the same entity. For example, if we export the definition of the check() function like in the below code, then we can safely use it in multiple units without breaking the ODR.
// ----------------------------
// bank.cpp (.ixx)
// ----------------------------
//...
export void check(account& a) { }
// ----------------------------
// bank_impl.cpp
// ----------------------------
module bank;
int account::transact(int amount) {
check(*this);
//...
}
// ----------------------------
// main.cpp
// ----------------------------
import bank;
int main() {
//...
check(acc);
}If we do the same with headers, for example by including bank.h in multiple translation units, that would break the ODR and we would get “multiply defined symbols” kind of errors, unless we inline the function.
Note how the definition of check() in the primary module interface is visible from inside the module implementation unit without any explicit importation. This is because the primary interface is implicitly imported by module implementation units and all of its declarations, regardless of whether they are exported or not, are visible (aside from those in the global and private module fragments).
Module implementation units are meant to provide the implementation for the module’s public interface and do not participate in its definition in any way. In fact, using export declarations in such kind of units is not allowed, that is the following will result in a compilation error
module bank;
export void check(account& a) { } // ERROR: Not a module interface unit
int account::transact(int amount) {
check(*this);
//...
}All of the tested compilers support both interface and implementation units and are able to build the code in Example 2.
However, building the code was not so straightforward with all compilers as I had to deal with several compilation quirks for the different module units. I was not expecting a uniform usage by simply doing import bank; with all of them (as it should be) but that was a bit too much for such very simple code.
2. Importing external entities
Programs usually need entities from external resources, such as the standard library, so we’ll need a way to include them in our modules. For example, suppose we want to extend our account class in Example 2 by adding functionality to get an account statement in textual format. Then we’ll need to bring at least the <string> facilities from the STL in the module. There are 3 ways to accomplish this.
- Importing from a modular library
- Importing as a header unit
- Including the header file
2.1 Importing from a modular library
The “native” module solution would be one that allows the developers to import the required library interfaces as with any other module. In the STL case it would mean simply doing import std.*. This looks very familiar for anyone using modules in other languages where the dotted notation is very common when using packages of modules (we’ll see this in another section).
// EXAMPLE 3
export module bank;
import std.string;
export class account {
public:
int transact(int amount);
std::string create_statement();
private:
int balance{0};
};Gotcha #3 Unfortunately the above use case is not supported across the tested compilers as it requires vendors to provide the STL functionality in modular format, something that's currently either not available, very tool-dependent or "experimental". At the time of this writing, MSVC comes with an experimental C++20 modular STL but it doesn't feel stable as yet. CLANG provides some support thru libc++ but it requires using its own implementation by means of their specific "map files". And GCC does not provide a modular STL at all. Also, even with full compiler support there is no standard for how the STL should be modularized, which may be a problem for cross-platform development. For example, the string facilities in Microsoft's modular STL are provided by thestd.coremodule notstd.string, as many would probably expect.
2.2 Importing as a header unit
Header files can be imported into modules through a process referred to as “include translation”, which converts them into a modular version called header unit. These are essentially BMIs synthesized by extracting the interface from the code in the header files, along with any macros, which are made available to importers. Header units do not provide all the same benefits of real modules but are safer to use than plain .h files as they have better isolation.
When imported, code from header units is not affected by the importing code or that of other headers. However, unlike importing modules, importing a header unit will make all of its declared entities available to the importing code (all declarations are implicitly exported). Also, in order to be translated into a safe header unit, a header file must be “importable”, that is it must meet the conditions that allow importing it without breaking the code of the importer.
In our example above, if we want to import the string header from the standard library as a header unit we would just need to do an import <string>; (note the semicolon at the end!), like so
// EXAMPLE 3
export module bank;
import <string>;
export class account {
public:
int transact(int amount);
std::string create_statement();
private:
int balance{0};
};That’s in theory. In practice, just enabling C++ 20 support with a compiler switch is often not enough and the road to seamless adoption is still pretty rough.
Gotcha #4 Not surprisingly, this solution does not work out of the box with all compilers. GCC fails to import the<string>header unit with the following error messageerror: failed to read compiled module: No such file or directoryA quick search revealed that this C++ Modules feature in GCC is not fully supported. Specifically, among other things, the docs state that "The Standard Library is not provided as importable header units. If you want to import such units, you must explicitly build them first.". Hence the file not found error. Similarly, CLANG had the same problem of being unable to find the header unit and came up with the following errorerror: header file <string> cannot be imported because it is not known to be a header unitAfter some hacking and experimentation I managed to find out the flags to perform the header translation and have it compile. However, it required an additional import for the string header in the module implementation unit, which should not be necessary as the declarations in the primary interface's purview should be implicitly accessible from there. I also had to remove the importation of<iostream>in the main.cpp due to conflicts with the importation of<string>. After some more research it appears that CLang is using its own C++ module feature as a bridge to Standard C++ Modules. The Clang feature (enabled with-fmodules) uses "map files" to resolve classic header files to header units and there are several details to be learned in order to understand their mechanics. Probably the used compiler commands are not correct or maybe this bridging is still buggy. In any case, I didn't investigate further as learning compiler-specific module implementations in order to use a "standard" language feature makes me a bit uneasy. On the other hand, MSVC built the code with no issues and without tweaking (using the Visual Studio IDE), implicitly doing all the header translation work.
2.3 Including the header file
Plain old header files can be included in the global module fragment section, which is purposely designed to make modules work with legacy headers
// EXAMPLE 3
module;
#include <string>
export module bank;
export class account {
public:
int transact(int amount);
std::string create_statement();
private:
int balance{0};
};Note that declarations in header files included in the global module fragment are in the global modules’ scope and only available to the including unit. Other units of the same module, such as implementation units, must include them explicitly . Also, header files should not be included in the module’s purview as that would make all their declarations (including unneeded ones) part of the module, thus polluting its scope.
This solution choked GCC with segmentation faults for some reason (apparently a bug), while CLANG built it but again disabling specific code because of internal errors. MSVC was happy with it and compiled everything with no issues.
3. Hiding implementation details
Another way to encapsulate implementation details in a module is by using the private module fragment. Consider our banking example where we don’t want the clients to deal directly with the account implementation. To achieve this, we can provide an interface that prevents direct manipulation of the account class, for example by exporting functions that operate on an opaque type, and put all the details of the account functionality in the private module fragment, like in the following example
// EXAMPLE 4
export module bank;
class account;
export {
account* login(int cid);
void deposit(account* a, int amount);
}
// Implementation
module : private;
class account {
public:
int transact(int amount) {
//...
return balance;
}
private:
int balance{ 0 };
};
account* login(int cid) {
// return the account for this client id
}
void deposit(account* a, int amount) {
a->transact(amount);
}Note that the approach used in this example is just for the sake of simplicity to demonstrate the purpose of the private module fragment. In real-world scenarios we would use a more “C++’ish” approach such as the Pimpl idiom or abstract interfaces.
As can be seen, the module does not export the account class and its definition is within the private fragment, which makes it totally inaccessible (or not “reachable” using C++ Standard jargon) to client code. Attempting to use it directly would result in errors.
import bank;
int main() {
auto acc = login(1);
acc->transact(100); // ERROR: 'account' is inaccessible
deposit(acc, 100);
}
If we remove the private fragment declaration, the account class would still be not visible to the importing code as it is not exported by the bank module interface and can’t be looked up. This means that resolving that symbol would fail, as shown in the following code.
import bank;
int main() {
account a{}; // ERROR: 'account' is undeclared
//...
}However the definition of the account class is still reachable as it is even so available to the compiler thru the opaque pointer, meaning that it can affect the behavior of the importing code. The following code, in fact, would not result in errors.
import bank;
int main() {
auto acc = login(1);
acc->transact(100); // OK without the private fragment
}The concepts of reachability and visibility seem to be key to fully understand the semantics of C++ Modules, and the Standard has a plethora of rules to define what they mean and how they apply in different contexts. Below are general definitions that apply broadly. For more specific and precise details refer to the official C++20 Standard.
3.1 Visibility
A declaration in a module is visible if it can be found by a name lookup mechanism and thus be directly usable from the importing code. All the exported declarations are visible to the importing code, while non-exported ones are visible only within the same module unit or to all units within the same named module if imported either implicitly or explicitly.
3.2 Reachability
A declaration in a module is reachable if it can potentially affect the behavior of other translation units that import the module, regardless of whether it is exported (i.e. visible) or not. In the previous example, if the account class was not in the private fragment it would be reachable even though it’s not exported.
Another important thing to note is that there can be only one module unit with a private fragment in a named module, meaning that the module will be comprised of only that unit. The purpose of the private module fragment is, in fact, that of allowing the implementation of a module in a single translation unit without making all the declarations reachable to the importing code. This means that we can implement, for example, the Pimpl idiom in only one unit without leaking implementation details through the interface.
Gotcha #5
The above code fails with GCC, apparently because of lack of support for private module fragments.
sorry, unimplemented: private module fragment
Aside from GCC, the other compilers were able to build the above example
4. Module decomposition
In real world scenarios we deal with large complex applications that require decomposing them into smaller more manageable pieces for better decoupling, maintenance and testing. Modules represent the perfect tool to perform such decomposition, and with C++ Modules this can be achieved using different approaches
- Using partitions
- Using “sub-modules”
While the end goal of these methods seems very similar, they’re not interchangeable and the reasons for choosing one over another may be quite different. Also, module usability is generally affected by the way modules are decomposed.
4.1 Partitions
In the above examples we have seen how the module interface and its implementation can be separated by including them into a module interface unit and a module implementation unit, respectively. But there are, however, limits with this approach. Consider the following example
// EXAMPLE 5.1
// ----------------------------
// bank_i.cpp (bank.ixx)
// ----------------------------
export module bank;
export class teller {
public:
void open_account(int cid);
void close_account(int cid);
void withdraw(int cid, int amount);
void deposit(int cid, int amount);
};
// ----------------------------
// bank.cpp
// ----------------------------
module bank;
void teller::open_account(int cid) {
customer c{}; // ERROR: 'customer' undefined
//...
database db{}; // ERROR: 'database' undefined
db.put_customer(c);
}
void teller::close_account(int cid) {
database db{}; // ERROR
customer c = db.get_customer(cid); // ERROR
//...
}
void teller::withdraw(int cid, int amount) {
database db{}; // ERROR
db.get_customer(cid) // ERROR
.get_account()
.transact(amount);
}
void teller::deposit(int cid, int amount) {
//...
}
// ----------------------------
// bank_impl.cpp
// ----------------------------
module bank;
class account {
public:
int transact(int amount) {
balance += amount;
return balance;
}
private:
int balance{ 0 };
};
class customer {
public:
account& get_account() {
return saving;
}
private:
account saving;
};
class database {
public:
customer get_customer(int cid) {
return customer{};
}
void put_customer(customer& c) { }
};Our bank module exports a teller interface for banking operations and implements such operations in a module implementation unit (bank.cpp). Another unit (bank_impl.cpp) implements internal banking functionality that are used by the teller class. We could write the whole module in a single file as this is just a toy example but in real-world large applications separating the interfaces from implementation details is a good practice. And this is also true with modules to avoid issues that will be discussed in the following section.
Trying to compile the above code will fail with “undefined type” kind of errors. The reason is that declarations in module implementation units are not shared with other units of the same module. Entities declared within a module implementation unit are only visible within that unit, so the customer and database classes are not visible to the teller. In order to share declarations, these should be included in the primary interface module, which is implicitly imported by all implementation units. That is, we should do something like the following
// EXAMPLE 5.2
// ----------------------------
// bank_i.cpp (bank.ixx)
// ----------------------------
export module bank;
export class teller {
//...
};
// Internal classes declarations
class account {
//...
};
class customer {
//...
};
class database {
//...
};
// ----------------------------
// bank.cpp
// ----------------------------
module bank;
// OK to reference 'account', 'customer' and 'database'
// as they're implicitly imported thru the PIM
//...
// ----------------------------
// bank_impl.cpp
// ----------------------------
module bank;
int account::transact(int amount) {
//...
}
account& customer::get_account() {
//...
}
customer database::get_customer(int cid) {
//...
}
void database::put_customer(customer& c) {
//...
}This will work, but there are a few problems with exposing so many information in the interface. First of all, those classes are internal details and do not belong in the primary interface. Even though they are not exported and thus not visible to clients, they produce unnecessary clutter. But more importantly, clients of this module will have a physical dependency on such details and every time they change, the interface (and its dependent code) need to be recompiled.
With header files this problem could be worked around using common C++ idioms such as the namespace detail to keep this internal information separated from the public interface and then including the header, or by exposing the teller interface using a Pimpl. In either case we would pay with the lack of real encapsulation and runtime overhead.
Instead, C++ modules provide a mean to share implementation details between module units without exposing them to the outside world and without any runtime overhead by using module implementation partitions. Unlike module implementation units, implementation partitions can be imported by other units of the same module and their declarations made accessible to the importing code. The above example can then be rewritten as follows
// EXAMPLE 5.3
// ----------------------------
// bank_i.cpp (bank.ixx)
// ----------------------------
export module bank;
export class teller {
public:
void open_account(int cid);
void close_account(int cid);
void withdraw(int cid, int amount);
void deposit(int cid, int amount);
};
// ----------------------------
// bank.cpp
// ----------------------------
module bank;
import :impl; // Import the implementation partition
void teller::open_account(int cid) {
customer c{}; // OK: 'customer' is visible
//...
database db{}; // OK: 'database' is visible
db.put_customer(c);
}
void teller::close_account(int cid) {
//...
}
void teller::withdraw(int cid, int amount) {
database db{}; // OK
db.get_customer(cid) // OK
.get_account()
.transact(amount);
}
void teller::deposit(int cid, int amount) {
//...
}
// ----------------------------
// bank_impl.cpp
// ----------------------------
module bank:impl; // Implementation partition
class account {
public:
int transact(int amount) {
balance += amount;
return balance;
}
private:
int balance{ 0 };
};
class customer {
public:
account& get_account() {
return saving;
}
private:
account saving;
};
class database {
public:
customer get_customer(int cid) {
return customer{};
}
void put_customer(customer& c) { }
};By making the module unit bank_impl.cpp a module implementation partition (module bank:impl) its declarations are made visible to the teller module unit by simply being imported.
Another interesting fact is that the internal details in the implementation partition are private within the module not just by convention but as a compiler-enforced policy. They can be used by all the units belonging to the same module but cannot be exported outside of it, not even by mistake. In fact, trying to do so will result in a compilation error
export module bank;
export import :impl; // ERROR: declarations in implementation
// partitions can't be exported
export class teller {
public:
void open_account(int cid);
void close_account(int cid);
void withdraw(int cid, int amount);
void deposit(int cid, int amount);
};Gotcha #6 GCC seems to recognize partition units without further hacking and correctly compiles the implementation partition code. However, it also compiles the example above where the primary interface tries to export the implementation partition, which is a bug as this would make its internal entities available outside of the module, thus defeating its purpose. CLANG was not able to compile the code as apparently module partitions are not yet supportedbank_impl.cpp:1:12: error: sorry, module partitions are not yet supportedMSVC supports and compiles implementation partitions. It also correctly fails when trying to export them with a message explaining that these units cannot be exported because they are not interface units. However, implementation partitions are not recognized out of the box and a specific compiler flag must be used (/internalPartition) in order to compile them.
Module partitions can also be interface partitions, which are useful to decompose a primary module interface into multiple parts. This is a common approach in real world applications to improve maintainability and also to avoid “fat interfaces” by following one of the SOLID principles for good software design (Interface Segregation Principle).
Consider again the above example of a bank module exposing a teller interface for banking operations. To follow design best practices, we would want to separate such operations into 2 distinct interfaces: one to provide accounting functionality and one to provide transactional operations.
This can be achieved by creating a bank:accounting and a bank:transaction interface partition, the former exporting a teller class for accounting operations and the latter exporting an atm class for money transactions.
// EXAMPLE 6
// ----------------------------
// bank_i.cpp (*.ixx)
// ----------------------------
export module bank;
export import :transaction;
export import :accounting;
// ----------------------------
// bank_acc_i.cpp (*.ixx)
// ----------------------------
export module bank:accounting;
export class teller {
public:
void open_account(int cid);
void close_account(int cid);
};
// ----------------------------
// bank_txn_i.cpp (*.ixx)
// ----------------------------
export module bank:transaction;
export class atm {
public:
void withdraw(int cid, int amount);
void deposit(int cid, int amount);
};
// ----------------------------
// bank_acc.cpp
// ----------------------------
module bank;
import :impl;
void teller::open_account(int cid) {
customer c{};
//...
database db{};
db.put_customer(c);
}
void teller::close_account(int cid) {
database db{};
customer c = db.get_customer(cid);
//...
}
// ----------------------------
// bank_txn.cpp
// ----------------------------
module bank;
import :impl;
void atm::withdraw(int cid, int amount) {
database db{};
db.get_customer(cid)
.get_account()
.transact(amount);
//...
}
void atm::deposit(int cid, int amount) {
//...
}
// ----------------------------
// bank_impl.cpp
// ----------------------------
module bank:impl;
class account {
//...
};
class customer {
//...
};
class database {
//...
};Unlike implementation partitions, interface partitions can be exported outside the module. Actually, they must all be exported by the primary interface as they contribute to the definition of the module’s public interface (note that no diagnostic is required). This is done by import-exporting the partitions using an export import :<partition>; declaration.
In our case, the accounting and transaction functionality are import-exported by the primary interface and can be used in client code by simply importing the module, for example like so
import bank;
int main() {
teller banker{};
banker.open_account(123);
atm money{};
money.deposit(123, 100);
}Implementation partitions can’t be exported but they can, however, be imported by all units within the same module, including the primary interface.
export module bank;
import :impl; // OK
//export import :impl; // ERROR
export import :transaction;
export import :accounting;Note that if we try to build the above example with GCC using a random compilation unit order, it may fail. The dependency graph of the involved modules is depicted in Figure 1
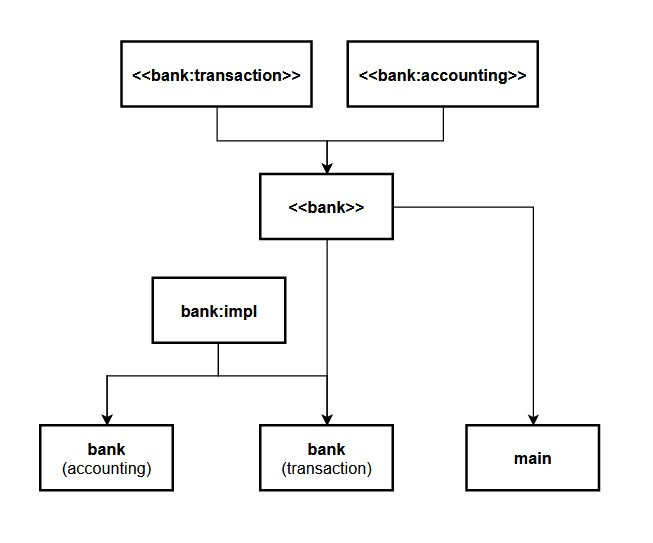
Due to these dependencies between modules, the compilation must follow a top to bottom hierarchical order where the modules at the top level that do not depend on anyone must be compiled first, and then those in the other levels down the hierarchy next. The code could be compiled only by changing the arrangement of the units in the build script, as shown here.
This problem was not evident when building the example with MSVC, likely because either the compiler or the IDE automatically took care of this.
4.2 Sub-modules
Another way to decompose a module is by splitting it into multiple logical sub-modules in a hierarchical fashion. The above banking example could be decomposed as in the following code
// EXAMPLE 7
// ----------------------------
// bank_i.cpp (*.ixx)
// ----------------------------
export module bank;
export import bank.transaction;
export import bank.accounting;
// ----------------------------
// bank_acc_i.cpp (*.ixx)
// ----------------------------
export module bank.accounting;
export class teller {
public:
void open_account(int cid);
void close_account(int cid);
};
// ----------------------------
// bank_acc.cpp
// ----------------------------
module bank.accounting;
import bank.impl;
void teller::open_account(int cid) {
//...
}
void teller::close_account(int cid) {
//...
}
// ----------------------------
// bank_txn_i.cpp (*.ixx)
// ----------------------------
export module bank.transaction;
export class atm {
public:
void withdraw(int cid, int amount);
void deposit(int cid, int amount);
};
// ----------------------------
// bank_txn.cpp
// ----------------------------
module bank.transaction;
import bank.impl;
void atm::withdraw(int cid, int amount) {
//...
}
void atm::deposit(int cid, int amount) {
//...
}
// ----------------------------
// bank_impl_i.cpp (*.ixx)
// ----------------------------
export module bank.impl;
export {
class account {
//...
};
class customer {
//...
};
class database {
//...
};
}In this example the bank module has been decomposed into 3 sub-modules
- bank.transaction
- bank.accounting
- bank.impl
This is very similar to the design implemented with partitions. However, while the end result may seem identical and one can still use the module in the same way, there are some notable differences.
Unlike partitions, sub-modules are not a C++ Modules feature. They are merely a convention for code organization. A mod.submod module is not a special entity but just a standard C++ named module. The dotted notation does not enforce any sort of hierarchical relationship. This is unlike other languages such as Python and Java where the dotted notation is part of the syntax and has a direct relationship with the files organization in the system .
In the above example, bank.transaction is an ordinary C++ named module which could have been named in any other way (e.g. bank_transaction). And so are the bank.accounting and bank.impl sub-modules. There are 4 distinct modules in total: the 3 mentioned above and the “root” bank, which is yet another individual module.
These 4 modules are independent and isolated and cannot share any declaration outside of what is being exported in their respective interfaces. They can be individually imported and used, including the bank.impl, like in the following code
import bank.transaction;
int main() {
atm money{};
money.deposit(1, 100);
}Importing the implementation details is also possible as they are now in a standard module unit that can be imported by client code
import bank.impl;
int main() {
account acc{};
acc.transact(100);
}which is something that may not be desired, so it’s very important to understand the differences between these two modular design approaches
Partitions represent internal implementation details that outside client code should not be aware about and cannot directly reach. Sub-modules are simply a conventional and convenient way to group together related modules.
This is a key difference with the implementation using partitions. Partitions and sub-modules are not to be considered interchangeable but complimentary.
5. Conclusions
The first impression with the current state of the art is that you are not dealing with a built-in language feature but with the inclusion of an external library. There is still too much “integration concern” and complexity from implementations being leaked into the developer’s space, which shows with the amount of guesswork and hacking to be done in order to use them even with the toy examples presented here. And all this does not encourage their adoption for sure. Some issues, especially the dependency one, must be addressed to make them transparent to developers.
On the other hand, given its complexity and some questionable design decisions, it’s easy to imagine the difficulties for compiler and tooling vendors in implementing this feature and make it work as seamlessly as possible, especially in a backwards-compatible manner, with other established functionality. Even though the major modern compilers have considerable amount of support (MSVC being the most complete as it seems), this is still labeled as “experimental” in many cases, and indeed it doesn’t feel really stable as yet. Personally, I wouldn’t rush to use C++ modules in any production system for the time being.